
There is only one way to avoid criticism: do nothing, say nothing, and be nothing.
— Aristotle
Introduction

Figure 1: Panther Tank, Also Known As Panzer V. (Source)
I recently finished a course on Bayesian analysis from Statistics.com and I have been looking for application examples that will provide me with some experience using these methods. I like to compare the Bayesian solutions with the standard solutions (usually called Frequentist).
Today, I came across a problem known as the "German Tank Problem". In a nutshell, the German army during WW2 had an excellent tank called Panther and the Allies needed to know how many they would be facing after D-Day, but the Germans were not going to willingly tell them how many they had. The only information the Allies had available were some serial numbers from tanks that had been destroyed. This problem provides an excellent example of how one can derive useful information about a population given data from a relatively small sample set.
Background
Statistical Camps
There are a number of possible approaches to analyzing a statistical problem. The two approaches used in this post are:
- Frequentist
- A method of statistical inference that draws conclusions from sample data with the emphasis on the frequency or proportion of the data (Wikipedia).
- Bayesian
- A method of statistical inference that uses Bayes' rule to update the probability for a hypothesis as evidence is acquired (Wikipedia).
Problem Statement
The Allies wanted to know the number of Panther tanks they would face because the Panther was a difficult opponent to stop. Some studies have shown that multiple Sherman tanks , the Allies' primary tank, were needed to defeat a single Panther. The only information available were the serial numbers of the gearboxes of destroyed Panthers, which were known to be numbered in their order of manufacture. To estimate the number of Panthers that were produced, the Allies used the statistics of these gearbox serial numbers (uniform distribution) to estimate the maximum serial number, which equaled the total number of tanks (one gearbox per tank).
I should mention that I do not know the format of the gearbox serial numbers. In many cases, the serial numbers include the year and month of production, followed by a number that reflects sequence of production for that month. In these cases, the serial numbers could be used to estimate the monthly production rate.
For this exercise, I am just going to assume that the serial number increments by 1 for each unit built over the entire lifetime of the product.
Monte Carlo Analysis
I am going to put together an Excel spreadsheet that I will use to:
- Generate a sequence of 10,000 numbers that represent tank serial numbers.
- Randomly sample 100 serial numbers from the population of 10,000.
- Apply the Frequentist and Bayesian population maximum estimators to the samples.
- Repeat this process 100 times and plot a histogram of the results.
My plan here is to be able to see how accuracy of the maximum estimators vary over 100 sets of 100 random samples. The correct answer is always 10,000.
Analysis
Sample Generation
I performed my Monte Carlo simulation using an Excel workbook and a VBA routine that generates 100 unique random integers from the range 1 to 10,000.
I show the VBA routine that generates my serial number samples below. The routine is a modified version of a routine I saw on Ozgrid. It works as follows.
- Create an array from 1 to 10,000 with each array element loaded with its index.
- For each array index, swap its contents with a randomly chosen array element.
- Pick the bottom k elements of the array as the sample set.
- Find the maximum of the k-element sample set.
- Return the maximum sample value to the spreadsheet that needs it.
The VBA routine is shown below.
Function RandSamples(Bottom As Integer, Top As Integer, _
Amount As Integer) As Double
Dim iArr As Variant
Dim i As Integer
Dim r As Integer
Dim temp As Integer
Dim maxi As Integer: maxi = 0
Application.Volatile
ReDim iArr(Bottom To Top)
'Generate array of all the serial numbers
For i = Bottom To Top
iArr(i) = i
Next i
'Mix the serial numbers randomly in the array
For i = Top To Bottom + 1 Step -1
r = Int(Rnd() * (i - Bottom + 1)) + Bottom
temp = iArr(r)
iArr(r) = iArr(i)
iArr(i) = temp
Next i
'Take your samples from the bottom k array indices.
'Find the maximum of your sample set.
maxi = -1
For i = Bottom To Bottom + Amount - 1
maxi = Application.WorksheetFunction.max(maxi, iArr(i))
Next i
RandSamples = maxi 'Return your sample maximum.
End Function
Frequentist Approach
The Frequentist approach is simple. You can derive a minimum-variance, unbiased estimator that is a formula that estimates the population maximum by assuming the sample maximum is biased below the population maximum by the average spacing of the samples.
Using this approach, the Frequentist estimator of the population maximum is shown in Equation 1.
| Eq. 1 | 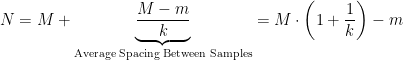 |
where
- N is the estimate for the largest member of the population (i.e. the number of tanks).
- M is the maximum sample from the sample set.
- m is the minimum sample from the sample set.
- k is the number of samples in the sample set.
Figure 2 shows a histogram of the Frequentist population maximum estimator (Equation 1) for 100 sets of 100 samples.

Figure 2: Distribution of 100 Maximum Estimates Using the Frequentist Model.
Bayesian Approach
The Bayesian population maximum estimator formula is shown in Equation 2. You can see the derivation here.
| Eq. 2 |  |
Figure 2 shows a histogram of the Bayesian population maximum estimator (Equation 2) for 100 sets of 100 samples.

FIgure M: Distribution of 100 Maximum Estimates Using the Bayesian Model.
Conclusion
This was a good example of how seemingly unimportant information (serial numbers) can be used to generate useful information. I have seen this approach used in a number of places to estimate the production of products, like iPhones.
This technique is now well-known enough that people are even talking about encrypting serial numbers to prevent competitors from deriving sales information on their products.