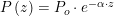Quote of the Day
Every boy in the streets of Göttingen knows more about 4-dimensional geometry than Einstein.
— David Hilbert, a first-class mathematician in competition with Einstein for developing general relativity. The boys in Göttingen sound pretty impressive to me.

Figure 1: Salt Boats Being Used to Carry Tourists. (Wikipedia)
I just came back from a business trip to Aveiro, Portugal. What a beautiful place! It is a very vibrant university town that lies about 6 km from the ocean. It is known as the "Venice of Portugal" because of its system of canals, which is a legacy of the old days when Aveiro was a major source of sea salt for the region (Figure 1). The climate is warm, with a very substantial breeze that blows out toward the Atlantic ocean. I liked my visit so much that I plan on bringing my wife on a future trip.

Figure 2: Butterfly in Pavement. (Source)
I was in Portugal visiting the University of Aveiro, which is an exciting place with much engineering activity. Portugal is working hard to develop a high-tech industrial base. They have some excellent electronics and optics design capability at the university and are performing some very high tech manufacturing at local commercial firms. These manufacturing firms also have a significant capability for servicing electronic products that are returned by customers. As you might expect, these manufacturers are located near the university – you see the same symbiotic relationship between schools and industry throughout the US. I was quite impressed.

Figure 3: Transistor Symbol. (Wikipedia)
As an amateur builder, I always look closely at how construction practices differ around the world. One novel aspect of Portuguese construction is Portuguese pavement, a type of stone pavement into which decorative patterns or symbols are inlaid (Figure 2). Most of patterns I saw were very artistic, e.g. wave patterns or stain glass-like figures, but one inlay in Aveiro of an NPN transistor symbol shows that not all patterns are artistic (Figure 3). I spent a few minutes watching some workers repair a damaged inlay – the work required a tremendous amount of labor and artistic talent. We do not have that kind of patience in the US.

Figure 4: Movie Poster for The Miracle of Our Lady of Fatima. (Wikipedia)
While driving to Aveiro from Lisbon, I passed the city of Fatima. As a lapsed Catholic, this name is very familiar to me. I vividly recall from my youth watching the movie The Miracle of Our Lady of Fatima (Figure 4). I found the story very compelling as a child, and I was not going to pass up an opportunity to visit the site.
I must admit that I was stunned when I arrived at the Sanctuary of Fatima – it was huge. The place was a beehive of activity because Pope Francis was going to visit the site for the 100th anniversary of the miracle (13-May-2017). This was making visiting the shrine expensive for the pilgrims coming to the site. I was told that during the Pope's visit, cots were renting for 1000 € per night – that is a huge sum for anyone and especially for Portugal. I really enjoyed my visit there, and I highly recommend it for anyone who happens to be in the area.
Figure 5 shows a panoramic view of the Sanctuary of Fatima. The scale of the site was incredible.

Figure 5: Fatima Basilica. (Wikipedia)